Postgres Table Replica Identity
Intro
This is the first part of our deep dive into Postgres logical replication. In this part, we will focus on the REPLICA IDENTITY property of a table and how it affects logical replication.
Table replica identity
Postgres tables require a replica identity to be configured in order to capture the changes made to the table. Replica identity specifies the type of information written to the write-ahead log with respect to what the previous values were.
By default, replica identity will use the table's primary keys as the identifiers.
Our goal with this blog post is to demystify the concept of replica identity and explain why you would want to alter your replica identity in certain situations. We also discuss performance implications and other factors to consider.
Components required for logical replication
The key components to logical replication:
- Table replica identity
- Write-ahead logs
- Replication slots
- Publications
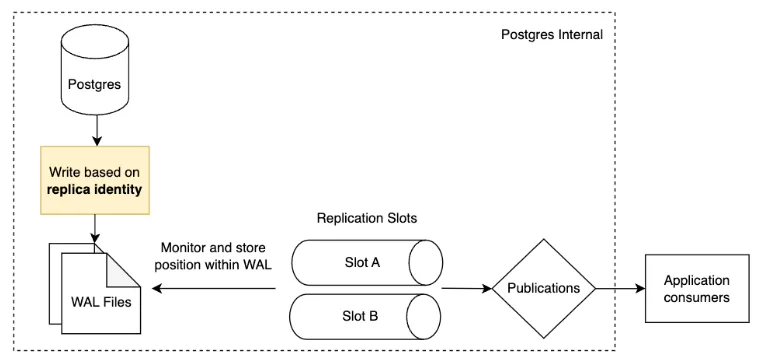
Notes:
- Replica identity will tell us what previous values to record
- Replication slots will monitor and record their own position within the WAL files
- An application will then need both a replication slot and a publication to start consuming changes from logical replication.
| Component | Description |
|---|---|
| Write-ahead logs | Postgres uses write-ahead logs (WAL) internally to record every database transaction. You can control how much information is written by toggling WAL_LEVEL, which we will cover in another blog post. |
| Publication | A publication is a collection of tables that you want to replicate. Changes made to those tables are then captured and sent to subscribers. You can create a publication with the CREATE PUBLICATION command. |
What are valid values to use for replica identity?
You can change a table's replica identity by running a command like this:
The valid settings are:
DEFAULTUSING INDEX index_name(must be unique)FULLNOTHING
For this section, we are using this as the example.
Default
The default replica identity is the primary key(s) of the table. If you are trying to replicate a table that does not have primary key(s), you can either alter the table to add keys (see our guide here), or you can modify the replica identity to be FULL.
Kafka message produced by Debezium
Partition Key:
Message:
USING INDEX index_name
The USING INDEX replica identity will capture the columns of the index you specify. The index must be unique and its columns must be NOT NULL.
Kafka message produced by Debezium
Partition Key:
Message:
Full
The FULL replica identity will capture all the columns of the table.
Kafka message produced by Debezium
Partition Key:
Message:
Nothing
The NOTHING replica identity will not capture any columns of the table. This will cause an error when you try to update a table with this replica identity.
Why would you consider changing the table's replica identity?
The main use case for changing replica identity is to change from DEFAULT → FULL. You would typically do this for two reasons:
- You don't want to deal with TOAST columns
- You need the previous row value
Scenario 1: you don't want to deal with TOAST columns
In a nutshell, TOAST columns are large columns where the values will not be written to WAL if the values did not change. This then means that your downstream application needs to understand the TOASTED value placeholder and handle it accordingly.
For Artie customers, we automatically detect and handle this by adding conditional update clauses.
If you’re not using Artie, you can handle TOAST columns by doing something like this:
To handle a TOAST column, we leverage CASE statements.
Scenario 2: you need the previous row value
One common reason we change replica identity to FULL at Artie is that we need the previous values in order to replicate a deleted row to a downstream table that has cluster keys specified.
For example, you may have a table called accounts, and in Snowflake the table is clustered by DATE_TRUNC('day', created_at). We will need the created_at for the previous row if we want to replicate a DELETE event.
Workaround
If you need created_at and don't want to change the replica identity, you can add created_at to be part of the table's primary key.
This is a great workaround for tables that have a lot of TOAST columns.
Impact on performance
TL;DR -
- Changing table replica identity from
DEFAULT → FULLon a table-by-table basis is mostly fine. - You should expect some increase to your database CPU with
FULLreplica identity.
By setting replica identity to FULL:
- There will be more information written into WAL files, which may increase your disk usage. That being said, WAL files are temporary since they are periodically purged, so the increase in disk usage is temporary.
- There will be more load on the network to propagate WAL to the replicas and subscribers, which may increase your CPU.
The actual incremental load depends on:
- The volume and distribution between
INSERT,UPDATE,DELETEevents.INSERTdoesn't have previous data, so it would not increase load. - How wide the columns are and whether there are a lot of TOASTed columns.
Click here to see benchmark data from Xata.


