Postgres CTID Scanning for Faster Backfills
Using CTID to backfill large tables 10x faster
Artie now offers an additional backfill method leveraging Postgres CTID scanning! This method results in 10x faster backfills for very large tables (>10 billion rows). We go into how CTID scanning works in this blog.
What is CTID?
In Postgres, the CTID field is a special column that exists in every table. It represents the physical location of a row within its table. Each CTID value is unique for each row in the table and is made up of a tuple (block number, tuple index within the block).
An example of a CTID looks like (42, 3), where:
- Block number (42) is the block in the data file where the row data is stored
- Tuple index (3) tells you the position of the row within the specified block
CTID is useful for certain low-level operations in Postgres, like when you need to quickly reference a specific row without any other unique identifier. With Artie’s CTID scanning, we use CTIDs to quickly split a very large table into shards and parallelize loading the table.
Note that because rows can be moved due to operations like VACUUM or updates that change row sizes, the CTID of a row can change over time. This is why we do not recommend using CTID as a long-term reference to a row.
When should you use CTID for backfilling?
There are nuances here, but we generally recommend running CTID backfills only if the following two conditions are true:
- If you have a very large table (>10 billion rows) and you want to backfill it very quickly
- You have a read replica available to use for backfilling – this is because there will be increased query load and shards calculation may take minutes to compute
How does it work?
First, Artie always leverages an online backfill strategy, such that the Postgres WAL does not accumulate storage from change data capture logs piling up and risk replication slot overflow.
Our online backfill strategy works like this:
- We employ two separate and parallel processes:
- Deploy a reader that consumes changes from the replication slot and publishes them to Kafka
- Deploy a separate reader that performs the backfill process
- Once the backfill (1) is done, we will then consume and drain the Kafka topic where changes are buffered
Now, specifically for CTID backfills, process (1) changes slightly to shard the tables and process shards in parallel. It looks something like this:
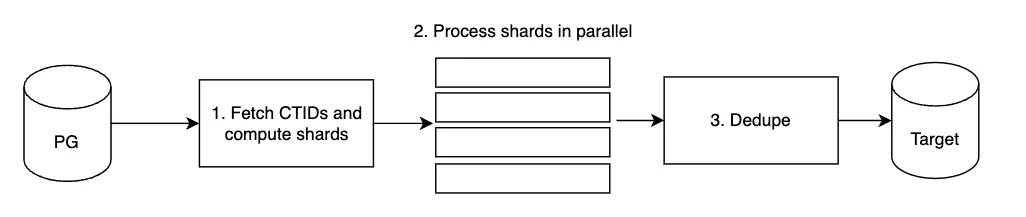
In order to not compromise the overall performance and stability of the database, we also have the following settings built in to our CTID backfill process:
- Shard size: the number of rows in each shard. By limiting the number of rows each shard contains, the system can manage backfills more efficiently. It also helps minimize the impact on the database’s performance, as scanning smaller datasets is generally quicker and less resource-intensive
- Max parallelism: the number of shards that are processed in parallel. Managing the level of parallelism helps balance the workload across the system and avoid overloading the database’s processing capabilities
- Backfill process CPU limit: this setting is a process level control that sets a CPU usage limit for the backfill process. The purpose of this is to cap the CPU usage of the backfill task so it does not degrade the performance of other processes and cause noisy neighbor problems
How to enable CTID backfills with Artie
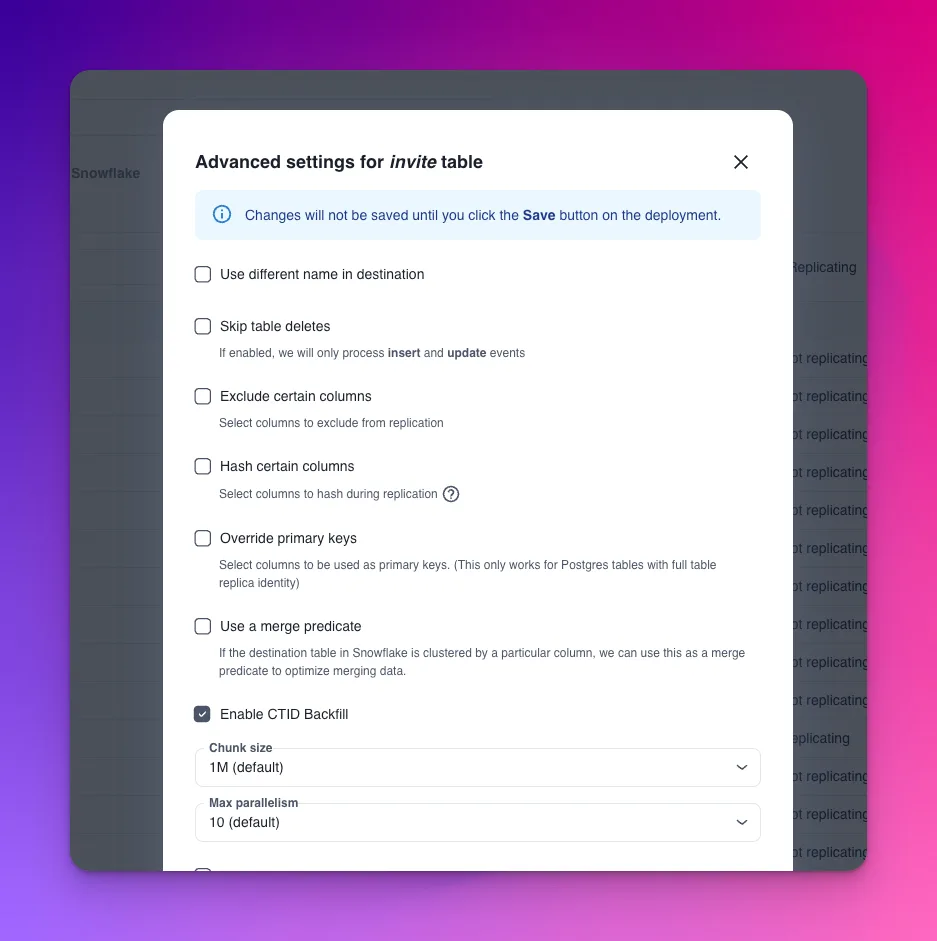
You can enable CTID backfills through table advanced settings. Please contact us at [email protected] if you run into any issues or have questions about this feature!


