MySQL Cascading Changes and Best Practices
Cascading changes
Cascading changes are used as a way to ensure referential integrity between related tables. Referential integrity refers to the fact that all references in a database are valid.
Consider the following table:
Which would create tables that look like this:
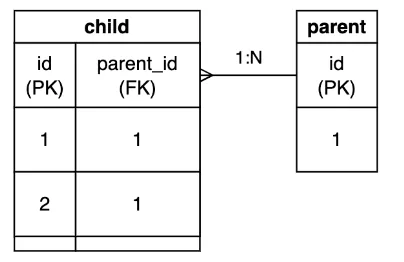
- In the child table, we have rows that are referencing the parent table (id = 1). As this is set up with as a foreign key constraint, we cannot delete the parent row with id = 1 without first deleting the child rows that reference it.
- However, with cascading deletes, we can delete the parent row and have the child rows automatically deleted.
You can use cascading changes to automatically apply certain actions to child tables based on what has occurred on the parent table. In this blog, we'll do a deep dive of cascading changes and reasons why you shouldn't use them.
Types of cascading changes
- Cascading updates (ON UPDATE CASCADE)
- Cascading deletes (ON DELETE CASCADE)
Cascading updates
Cascading updates will detect primary key updates and automatically update references in the child table. To enable this, we would do something like this:
If I then update the primary key of the parent, all the child references will be automatically updated.
In practice, we rarely would use cascading updates as we would try to avoid and minimize the amount of times we would need to change a table's primary keys since it could impact external applications.
Cascading deletes
Cascading deletes will detect a delete in the parent table and automatically delete all the referenced child rows. To enable this, we would do something like this:
With cascading deletes, if I deleted an entry from the parent, the respective child entries will be automatically deleted.
How are cascading changes different from triggers?
| Cascading changes | Triggers | |
|---|---|---|
| Purpose | Maintaining referential integrity. | Can be used to execute a set of specific SQL statements. |
| Comments | - | Database triggers offer more expressive ways to execute code based on specified database changes such as insert, update and deletes. |
The key differences are:
- Database triggers are more expressive than cascading changes, it can be used to execute arbitrary SQL statements based on specified database changes.
- Changes from a database trigger will show up in binlogs, whereas cascading changes will not. This may be an important consideration if you are using log-based replication.
Why do we not recommend it in production?
- Cascading changes makes the database more susceptible to unintended changes
- Deleting a record in the parent may trigger mass deletes to other child tables
- You will most likely want to archive or soft delete the data instead of hard delete in order to keep it for historical purposes
- It's extremely difficult to recover from an unintended delete as row changes will not appear in binlogs
- If a deleted record has related records that needs to be deleted first, it's better to block and have users explicitly delete the dependent records first
- For example: If you are an e-commerce company, and you delete a row in the
productstable and theorderstable is set to cascade delete, you will lose all the order history for that product
- It makes debugging more difficult as other team members may not be cognizant of it
- Cascading changes are also bad for performance as it requires a serializable lock
- A serializable lock will hold an exclusive lock on the resulting data and will block other transactions and queries from accessing the locked rows
- This may lead to deadlocks and slow running queries
How do you remove cascading changes if you have it enabled?
To remove cascading changes, you will need to recreate the constraint, below is a snippet of how you would do it:
First, you'll need to find the foreign constraint name
Once you have the constraint name, we can recreate it.


